Introduction
This article provides an introductory overview of Multivariate Analysis (MVA) including a brief review of some of its benefits and limitations. The manuscript intends to demonstrate that there may be opportunity to further the use of MVA tools at early stages of investigations as a routine diagnostic tool using medium-sized data sets as part of a more holistic approach to root cause identification. The article then briefly expands on case studies in which MVA tools were leveraged for initial diagnostics and to gather actionable information on potential opportunity areas.
Multivariate Analysis has been described by Divino as a “set of statistical models that examine patterns in multidimensional data by considering, at once, several data variables”.1 Today’s widespread availability of computers coupled with ever-increasing computing capabilities – even for average office configurations – makes leveraging MVA for routine diagnostic purposes a possibility. As stated by Olkin and Sampson “with the continued and dramatic growth of computational power, multivariate methodology plays an increasingly important role in data analysis, and multivariate techniques, once solely in the realm of theory, are now finding value in application”.2 There is arguably an opportunity to further expand the use of MVA tools especially for initial investigational assessments with medium-sized data sets. This perceived gap may relate to multiple factors. However, we should not underestimate the potential benefits of incorporating MVA on a day-to-day basis as a complementary tool to help identify seemingly elusive root causes.
Benefits of Multivariate Analysis
There are tangible benefits for using Multivariate Analysis tools and the intention is to review some of the relevant ones in this section. From a high-level perspective, a fundamental benefit of MVA tools is to help extract knowledge from data. Mercer et al. assert that “one of the most common phrases used when discussing the benefits of MVA is its ability to convert data into information”.3 In other words, MVA tools support data mining in ways to discern relevant factors that may be used to steer behavior of your variable(s) of interest.
When going through procedural specifics of MVA tools, there are also advantages such as simplified visualization of complex data sets via reduced number of principal components or latent variables.
According to Dempster “balance makes possible the efficient storage of data as multiway arrays where the labeling of individual values of variables can be represented very compactly [….] The benefi ts include […] simpler interpretation of the results of analysis”.4 Combining numerous variables into a limited set of principal components or latent variables by merging projections into common planes to reduce data dimensionality can significantly simplify both visualization of input data and interpretation of MVA results.
Another benefit of MVA tools is help reveal empirical relationships and interactions among different variables which represents a more holistic approach versus univariate (‘one-independent-variable-ata-time’) approaches. Batholomew states that “with multivariate data […] there is now the possibility of investigating the relationships between variables”.5 MVA tools not only help understand relative behavior between each independent variable (Xn) and the variable of interest (Y), but also helps visualize combined interactions between variables and confirm if a set of factors is more relevant to explaining (Y) behavior than only focusing on a single suspected variable. MVA tools are also capable of analyzing diff erent types of inputs as “the data may be metrical, categorical, or a mixture of the two”5 which means data sets can combine quantitative and qualitative data and still be able to perform concurrent analyses.
Limitations of Multivariate Analysis
Multivariate Analysis tools are not infallible. There are limitations and it is important to understand them in order to reduce their influence in the analysis outcomes.
A basic checkpoint for all types of modeling – not just MVA – is to ensure the quality and representativeness of training data sets, as the principle ‘garbage in/garbage out’ implies. Oftentimes this is not necessarily under the control of the person performing the MVA. For example, while an experienced analyst may emphasize the need for a minimum quantity of representative data incorporating process variability sources (i.e., different batches, different material suppliers, variability in actual process and environmental parameters, data from golden batches and ‘out-of-spec’ batches, etc.) there are still aspects of the data that may lack desired accuracy or resolution levels. An example may be raw materials property values reported by vendors. Sometimes when comparing large amounts of raw material batches, they show little – if any – variability in property values one from the other. It seems there are not enough significant digits in the reported property values as to be able to clearly discern its impact using MVA techniques. In some cases, it may be recommended to performed in-house testing if the test resolution can be significantly improved.
Another limitation worth noting – more so in this article encouraging use of MVA for medium-sized data sets – is that, as a general rule of thumb, the larger the sample data set, the more reliable the results of the analysis. As stated by Jackson “for multivariate techniques to give meaningful results, they need a large sample of data”.6 Keeping this in mind, medium-sized data sets can still help provide hints, but before getting to conclusions you should use the MVA outcomes complementary to other process historical information and investigation tools, and consider increasing your MVA data set looking to either further confirm or challenge initial findings.
There are additional limitations and particularities to consider but it is not possible to expand on all of them due to article size constraints, so instead some of them are mentioned for awareness: minimize missing data values as possible, challenge for random correlations (casualty versus causality), and avoid overfitting – especially with medium-sized data sets for initial diagnostics, it is recommended to use a reduced number of principal components or latent variables.
A Look at Case Studies
This section intends to review actual case studies in which MVA tools were leveraged for initial assessments of medium-sized historical data sets. The activities are aimed at improving process understanding and identifying hints on the interrelationships of variables that may lead to reduce variability and increase process robustness.
Before reviewing the case studies, and in order to facilitate understanding and interpretation of results for readers with little or no experience with MVA tools, a short glossary of terms follows (Table 1).
Case Study 1
Scope: Preliminary diagnostic assessing the role of raw material properties on finished product dissolution variability for a non-sterile solid oral dosage form.
Description: This is a medium-sized historical data set that included raw material properties from testing results documented in certificates of analysis for the raw materials, and from finished product dissolution tests results.
Outcomes: A two principal components Partial Least Squares (PLS) model was fitted as part of initial diagnostic. Figure 1 provides a summary of fit for the model with a cumulative R2Y just over 30%.
Reviewing the Variable Importance to Projection (VIP) plot depicted in Figure 2, the top empirical variables influencing dissolution variability are preliminary identified as 1) high proportion of coarse material for confectioner’s sugar, and 2) high values for two properties of the Active Pharmaceutical Ingredient (API): Phenyl acid and water content.
Subscribe to our e-Newsletters
Stay up to date with the latest news, articles, and events. Plus, get special offers
from American Pharmaceutical Review – all delivered right to your inbox! Sign up now!
Exploring the relative variability of API properties values, which comprise two of the top three ranked VIP variables, MVA tools were used to compare API properties from two suppliers used for the manufacturing process. Figure 3 summarizes findings via a score scatter plot. The comparison revealed quantitative differences in the variability of API property values between suppliers. In terms of the first principal component (t1), while some overlapping is observed for API material property values and variability seems similar in terms of range, quantitative differences in average aggregate values are visually noted. In general, API Supplier 1 (batch scores in black color) aggregate average value arguably lies in the top/left quadrant of the plot, API Supplier 2 (batch scores in red color) aggregate average value lies somewhere in the right quadrants of the plot.

When considering differences in second principal component (t2), average aggregate values for the two suppliers seem to differ much less relative to t1. However, the variability of API Supplier 2 (red) is considerably larger – about double in range – than the dispersion of values observed for API Supplier 1 (black).
Actionable Information: The additional understanding of supplier differences in API material properties coupled with identifying the properties (phenyl acid and water contents) that influence our Y variable of interest the most, also gives actionable information once these correlations are confirmed with additional historical data and complementary process observations. Using this knowledge, potential actions aiming to reduce finished product dissolution variability may include: 1) Negotiate with API Supplier 2 to establish narrower acceptable ranges for these API properties, and/or 2) modeling may be leveraged to select API material batches based on their properties values to increase chances of attaining desired dissolution values.

In terms of dealing with a high proportion of coarse material for confectioner’s sugar, there are different ways that may be explored to reduce the proportion of coarse material. These may include adding or modifying sieving and/or milling process steps. At this stage it would be helpful to have a technology available to measure particle size distribution (PSD) as depicted in Figure 4. This way quantitative measurements can be evaluated in the MVA model to estimate the overall impact on finished product dissolution values before eff orts to incorporate any changes to the actual process.
Case Study 2
Scope: Leveraging historical data for preliminary diagnostics on the role of raw material properties and process parameters with severity of recurrent sticking issues at the tablet compression stage.
Description: This is a medium-sized data set compiled from historical data that included raw material properties from results captured in certificates of analysis, and actual process parameters as measured and recorded in master batch records during processing. The annotations on the number of stops due to sticking issues at the compression stage were used as an indicator of sticking severity.
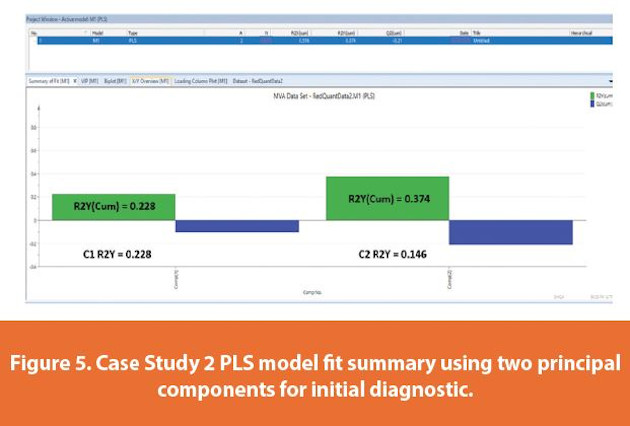
Outcomes: A two principal components PLS model was fitted as part of initial diagnostic initiatives. Figure 5 provides a summary of fi t for the model which exhibits a cumulative R2Y of 37.4%.
Looking at the results for the VIP plot in Figure 6, the top variables related to sticking severity were preliminary identified as 1) granulation time for one of the tablet layers formulation (bi-layer tablet product), and 2) small differences in quantity of two raw materials added as part of the bi-layer tablet formulation.
Actionable Information: The additional understanding of how higher granulation times for one of the tablet layers affects severity of stickiness at the tablet compression step is an important hint. The granulation process is stopped after reaching a threshold torque value measurement for the granulator motor, not using a fixed time. Thus, granulation times may be less variable if material is evenly and similarly spread throughout the granulator for each batch before starting the process. According to the loading column plot (Figure 7), the higher the process granulation time, the more severe sticking is observed at the tablet compression step. Also, there may be additional ways to improve uniformity in the addition of the granulating agent like using a pump for uniform spray rate of liquid instead of gravity feed addition.
The other variables identified relate to the quantity of two materials added to the process. Although formulation has a fixed theoretical value for raw materials, there is some small tolerance allowed in the actual weight of the materials. And according to MVA results the two materials identified – even in small quantity differences – relate to sticking severity. For example, let’s focus on the ingredient labeled as MetoCarb (Methocarbamol). According to Figure 7, the higher the MetoCarb added to the process, the higher the sticking severity. MetoCarb has a relatively low melting point. Thus, the longer high shear processes take – such as granulation – the higher the temperature the product reaches. This would also apply to other processes including compression and any in-process milling step performed. But from the MVA data set, the granulation step exhibited large variability in duration and the magnitude of the variability was empirically related to sticking severity. It is likely that the higher the granulation times and the higher the product temperatures, the more melting of MetoCarb occurs; and the more MetoCarb available during these high shear steps, the more there is to melt. Along with efforts to reduce variability and shorten granulation times, another consideration may include finding ways to reduce the rise of product temperature during high shear process steps.


Final Remarks
This article provided a high-level overview on Multivariate Analysis, reviewed some of its benefits and limitations, and intended to illustrate its usefulness as a routine tool for initial diagnostics leveraging medium-sized data sets. Actual case studies were briefly presented with emphasis on scope and outcomes for each case. The author argues that there is still opportunity to further increase the use of MVA tools on a more regular basis. Findings and hints from MVA can be a complementary source of knowledge for informed decision-making. MVA also aligns well to ‘smart manufacturing’ or ‘intelligence-based manufacturing’ initiatives while promoting a ‘right-first-time’ mindset to resolving issues.
Nowadays we often acquire tons of process data, yet sometimes when issues arise it is still difficult to identify a definitive factor or set of factors to label as the root cause. Instead, many investigations still seemingly rely on ‘one-independent-variable-at-a-time’ approaches which may prompt mixing inconclusive data with assumptions into technical rationales that funnel to ‘more probable causes’. Then focus quickly switches into establishing plans to avoid recurrence placing all bets on the potential suspect(s). In some extreme cases this may turn into trial and error iterative cycles. Robustness should be incorporated into our analyses by taking advantage of available contemporary tools and resources. But this needs to be done in a natural and organic manner. One that does not require additional considerable burden each time in order to happen. It means that – along with computing power availability – training of technical personnel is widespread at key levels of the organization and MVA software packages and tutorials are in place, and technical colleagues are encouraged to use these tools regularly to increase their confidence and proficiency, so widespread use of the tools on a routine basis becomes the new normal.
It is also important to have realistic and reasonable expectations from using MVA tools. While they can provide valuable insight, there are limitations which may be implicitly sourced in the data used, the analyst proficiency with the tools, or just the reality of your system of study. Interpretation of results need to consider limitations and particularities and use the information from MVA results in a complementary way. The aim is to improve the level of confidence for decision-making by leveraging a more holistic approach.
Acknowledgements
Many colleagues were directly and indirectly involved supporting the activities in the case studies described in this article. Since the list is too long to mention them individually, the author prefers to collectively thank the Pfizer network of technical colleagues that made these and other similar efforts possible.
References
- Divino, R. (N.S.). An Introduction to Multivariate Data Analysis: What it is, and some of the techniques at your disposal. Electronically retrieved on June 15, 2020 from Medium at https://towardsdatascience.com/an-introduction-to-multivariate-data-analysisece93ceb1ed3?gi=457be3114156.
- Olkin, I. and Sampson, A.R. (2001). Multivariate Analysis: Overview. Published in International Encyclopedia of the Social & Behavioral Sciences, 2001. Electronically retrieved on June 15, 2020 from ScienceDirect at https://www.sciencedirect.com/topics/medicine-and-dentistry/multivariate-analysis.
- Mercer, E.; Mack, J.; Tahir, F.; Lovett, D. (2018). Application of Multivariate Process Modeling for Monitoring and Control Applications in Continuous Pharmaceutical Manufacturing. Published in Multivariate Analysis in the Pharmaceutical Industry (Book), 2018. Electronically retrieved on June 15, 2020 from ScienceDirect at https://www.sciencedirect.com/topics/medicine-and-dentistry/multivariate-analysis.
- Dempster, A.P. (1971). An Overview of Multivariate Data Analysis. Published in Journal of Multivariate Analysis 1(3), September 1971, pp. 316-346. Electronically retrieved on June 15, 2020 from ScienceDirect at https://www.sciencedirect.com/science/article/pii/0047259X71900066.
- Batholomew, D.J. (2010). Analysis and Interpretation of Multivariate Data. Published in International Encyclopedia of Education (Third Edition), 2010. Electronically retrieved on June 15, 2020 from ScienceDirect at https://www.sciencedirect.com/topics/medicineand-dentistry/multivariate-analysis.
- Jackson, J. (2018). Multivariate Techniques: Advantages and Disadvantages. Electronically retrieved on July 11, 2020 from The Classroom at https://www.theclassroom.com/multivariate-techniques-advantages-disadvantages-8247893.html.
- MKS Umetrics AB (1998-2015). SIMCA 14.1 Help Electronic Manual installed in computer.
Author Biography
José-Miguel Montenegro-Alvarado is Manager of Process Analytical Technology (PAT) projects as part of Pfizer’s Global Technology & Engineering (GT&E)/Global Engineering (GE) / Process Monitoring, Automation and Control (PMAC) Team. Based in Puerto Rico, in his current role Montenegro is responsible for technical support and facilitates deployment of PAT to Pfizer’s Small Molecule Operations that include manufacturing sites for non-sterile Solid Oral Dosages (SOD) and Active Pharmaceutical Ingredient (API) operations.
Montenegro’s academic background includes Bachelor’s and Master’s degrees in Chemical Engineering at the University of Puerto Rico – Mayagüez with a minor equivalency in Economics. His professional career in the pharmaceutical industry started in 2001 at the Searle & Co. Caguas site after industrial internships in medical devices with Baxter and Techno-Plastics Industries. After mergers and acquisitions (Pharmacia, Pfizer), in 2007 Montenegro was recruited by Pfizer Center Functions as part of the Process Analytical Sciences Group (PASG). Throughout time Montenegro has interfaced with over 20 Pfizer sites in four different continents including United States, Puerto Rico, Australia, Argentina, Brazil, Italy, Mexico, Spain and Venezuela. In 2010 Montenegro transitioned into his current role as Manager – PAT projects.