Robert Dream - HDR Company LLC
The concept of continuous improvement is a philosophy of the industry and most pharmaceutical manufacturers as they strive to increase supply, gain efficiencies, and decrease costs, and is supported by applicable regulatory authorities. Innovations in the unit operations that make up the steps in the processing of conventional drug products are often the key to making such improvements. In the meantime, innovation and progress in technology, automation, and new drug product modalities, i.e.; in addition to small molecule, and large molecule/mAbs, the newer modalities, e.g., ATMPs/CGTs, ADCs, mRNAs, Oligos, and so on adds new layers of complexity into the fold. Solving complex and multi-faceted manufacturing problems in the design space using the available tools complicates math and science on a risk basis using current validation methods. Especially accommodating all modalities in the industry and satisfying various regulatory and regulations globally. Yet, to manufacture safe, pure, efficacious products meeting the required qualities will require using new tools and leading innovation and technologies, e.g.; Artificial Intelligence, Machine Learning, and Deep Learning. Utilizing newly invented intelligent, compact, and interchangeable machines/systems to fit the required processes that create the factory/facility of the future by using holistically connected and integrated production lines to bring about advanced manufacturing streams.
Over the last few years, the combination of massive data, open-source advances in deep learning (deep neural networks), and powerful hardware and computer or processing speeds have led to breakthroughs in a number of areas, including image classification, speech transcription, and autonomous driving. These advances have brought about tremendous economic implications.
Data scientists who attempt to deploy models find themselves wearing several hats: data scientist, software developer, IT administrator, and security officer. They struggle to build and wrap their model, serve their model, route traffic handle load-balancing, and ensure all of this is done securely. However, to achieve business value with AI, models must be deployed. Model deployment and model management are difficult tasks to complete, let alone automate.
The open-source community has only begun to create tooling to ease this challenge in model development, training, and deployment. Much of this work has been done by researchers at large companies and teams at startup-turned-enterprise companies like Uber and Netflix.
To start, Uber’s data scientists could only train their models on their laptops, inhibiting their ability to scale model training to the data volumes and compute cycles required to build powerful models. The team did not have a process for storing model versions, which meant data scientists wasted valuable time recreating the work of their colleagues. So, Uber built and continues to evolve its own machine learning operations (MLOps) platform, Michelangelo.13
While Uber and other companies have applied machine learning to innovate products, they did not start with a standard process for deploying their models into production, thereby severely limiting the potential business value of their work. Uber’s team reported having no established path to deploying a model into production, in most cases, the relevant engineering team had to create a custom serving container specific to the project.
To focus on building better models, data scientists at Google, Uber, Facebook, and other leading tech companies built their own AI platforms. These platforms automate the supporting infrastructure, known as the glue code, that is required to build, train, and deploy AI at scale. In the drug manufacturing industry, we have an added complication compared to the industries and that is, we manufacture drug products for the patient, which requires compliance with regulations, or in other words being safe, efficacious, pure, and meeting a required and specified quality.
What is Artificial Intelligence
Artificial Intelligence (AI) is defined as a technique that enables machines to mimic human intelligence. It enables machines to “think like humans”. Using these tools, it is possible to improve the efficiency of various decision-making processes but also to further drive innovation within an organization.
What is an AI Platform
An AI platform is an integrated set of technologies that allow team(s)/ organization to develop, test, deploy, and refresh machine learning (ML) and deep learning models. AI applies a combination of tools and techniques that make it possible for machines to analyze data, make predictions, and take action faster and more accurately than humans can do manually.
Enterprise AI platforms enable organizations to build and maintain AI applications at scale. An AI platform can:
- Centralize data analysis and data science collaboration
- Streamline ML development and production workflows, which is sometimes referred to as ML operations or MLOps
- Facilitate collaboration among data science and engineering teams
- Automate some of the tasks involved in the process of developing AI systems
- Monitor AI models and systems in production
What is Machine Learning
Machine learning (ML) goes a step further. It is a subset of AI that enables machines to improve autonomously through learning. This means that systems based on ML technology will improve incrementally while performing the tasks they were designed to execute. Who would have thought that even machines would start learning on the job? (Figure 1)
What is Deep Learning
Deep Learning (DL) is a type of machine learning based on artificial neural networks in which multiple layers of processing are used to extract progressively higher-level features from data. The prototype will use a combination of deep learning, natural language processing, and dynamic network analysis to detect and examine the cross-platform spread of disinformation.
Deep learning is a new term for an old concept: neural networks, which are collections of mathematical operations performed on arrays of numbers. But the models generated by deep learning techniques are significantly more complex or “deep” than traditional neural networks, and also involve much greater amounts of data, Figure 2.
AI, ML, and DL Relationship
A visual representation of how artificial intelligence, machine learning, and deep learning relate to each other, as seen in Figure 3. Artificial intelligence (AI) is a broad field that aims to create machines that can perform tasks “smartly”. Machine learning (ML) is a subset of AI that enables machines to learn and adapt through experience. Deep learning (DL) is a subset of ML that uses artificial neural networks to learn from large amounts of data and make intelligent decisions.
Different Types of AI and Process Validation Lifecycle
To fully understand where the difficulties for AI validation and Machine Learning validation lie, we can divide all systems into three main categories according to drug safety;
Validating intelligent automation systems in pharmacovigilance. Insights from good manufacturing practices:
- Rule-Based Static Systems
- AI-based Static Systems
- AI-based Dynamic Systems
1- Rule-Based Static Systems
The first category is rule-based static systems. This is by far the largest group, as most systems currently in use at life science companies fall into this category. Automation in these systems is achieved through static rules and fixed algorithms. The validation framework for these types of systems today exists in guidelines and regulations such as GAMP5® (Figure 4)9 21 CFR part 11,10 and Eudralex volume 4 annex 11.11
2- AI-based Static Systems
The second category is AI-based static systems. These systems use artificial intelligence but are not self-learning. Training and learning take place before release and can be repeated with each update. (Figure 5) Validation of these types of applications can usually be done according to current best practices and guidelines, but the AI component of these systems requires additional deliverables.
The non-AI functions of these systems require no additional validation effort beyond the usual good practices outlined in, for example, GAMP®5. The well-known V-model can be used with either a waterfall or an agile development approach and the deliverables consist of user requirements, functional, design and/or configuration specifications, installation tests, functional tests, and user acceptance tests, accompanied by a validation plan and summary report.
During this validation effort of the non-AI functions, some additional concerns should be considered when documenting and testing the AI component of the system. As with the non-AI portion, the AI component of the system must be validated. While the V-model deliverables are a good start, additional information or testing efforts must be documented to adequately cover the AI model during validation.
Important aspects to keep in mind for the concept phase of the system life cycle primarily concern the data selection used for both training and testing of the system. Since this will have a major impact on the outcome of the validation, it must be done with due care, knowledge, and expertise.
During the project phase of the system life cycle, the AI model should be described in model requirements and specifications. The design and training should be documented and conducted with the pre-selected set of training data and the result of testing the model based on the set of test data, the model requirements, and specifications should also be documented.
During the operation phase of the system, the production/life cycle data set should be monitored and continually reviewed to determine if changes in this data set may require an adjustment to the training and testing data set and trigger any retraining effort.
US FDA Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML) based Software as a Medical Device (SaMD), Discussion Paper and Request for Feedback, 2019.13
Overlay of the US FDA’s total product lifecycle approach on artificial intelligence/machine learning workflow.
3- AI-based Dynamic Systems
The third category is AI-based dynamic systems. Machine learning-based applications fall into this category. These types of systems change during the operational phase because of the machine learning aspect. The output of the system given a certain input might be different over time because the system learns.
Validation challenges are greatest in this category. The FDA proposal for an AI validation life cycle provides a first glimpse of where the focus should be to ensure that these systems are validated and maintained in a controlled state. Clear and practical regulations for this type of validation do not yet exist.
AI and ML Validation Requirements
For both technologies, several difficulties arise when we begin to look at the validation requirements. Classically, validated systems are set in stone from the moment they are released. Validation is usually only re-evaluated when major updates are made to the system. Fixed algorithms ensure that every input generates the same output every time.
AI/ML-based systems are more of a special case because of the training, retraining, and self-learning aspects of the software. To date, it is not yet possible to reverse engineer the thought process of AI or ML software, which makes it difficult to fully understand the software.
In practice, we call these systems black boxes. Their decision-making process is difficult to fully break down into testable pieces and when we look at ML-based systems, the process changes every time the system learns by performing the tasks it was put into service for. It can generate different outputs based on the training of the system.
Verifying and Validating AI Systems
(AI Platforms for Open-Source Data Science)
AI systems will only fulfill their promise to society if they can be relied upon. This means that the role and task of the system must be properly formulated; that the system must be bug-free, be based on properly representative data, and can cope with anomalies and data quality issues; and that its output is accurate for the task.
AI systems are becoming ubiquitous in innovative technologies and drug product and drug substance manufacturing lifecycle, ranging over medical diagnostic systems, similar to financial trading algorithms, driverless cars, customer engagement systems, and countless other areas. Sometimes performance of the AI is critical, in the sense that a patient could die, an accident could occur, or a business collapse if incorrect decisions are made. So, a key question is: can you trust your AI? How do you know it is doing what you want it to do? Such high-level questions have several aspects;
- Has the objective been properly formulated?
- Is the AI system free of software bugs?
- Is the AI system based on properly representative data?
- Can the AI system cope with anomalies and inevitable data glitches?
- Is the AI system sufficiently accurate?
Positive answers to all of these questions are required to have full confidence and trust in the performance of the system.
AI is not unique in having to address these questions, and analogous questions are central to many other domains. This has inevitably meant that various terms are used for different aspects, e.g.; the term “reliability” is used to describe the reproducibility of a measurement result under different conditions (so it refers especially to questions 3 and 4), while the term “validity” is used to describe whether the measurement procedure is tapping into the right concept (question 1). In software testing, a distinction is made between “validation” and “verification.” Validation refers to checking that the system specifications satisfy the customer’s need (question 1), while verification is checking that the software meets the specifications (especially questions 2, 3, and 4). Informally, validation is sorting out that you are answering the right question, and verification is ensuring that you find the right answer to that question. In machine learning, validation is often used in the narrow sense of ensuring that the predictions are sufficiently accurate. This is the subject of question 5 and might better be called “evaluation.”
Question 1 involves mapping real-world questions with all the ambiguity, uncertainty, and complexity of the real world to a formal mathematical description, which can be described in a programming language. This is basically an assessment of conceptual accuracy, asking whether the AI system is addressing the right problem. Answering question 1 may not involve data at all but could simply require elaborate exploration of design documents and specifications in an effort to detect problems, anomalies, or oversights, as well as the possibility of a system being presented with unexpected conditions. The complexities of the real world mean that guaranteeing the adequacy of this mapping will often be impossible, and the best one can do is to try to think of all possible scenarios that could arise. Question 1 also involves ethical issues, for example, the question of whether or not an AI personnel selection system discriminates. This example also illustrates the complexity of the challenge, since there are several, mutually incompatible definitions of discrimination, one of which must be chosen for the system.
Questions 2–5 involve more mathematical exercises. Given a well-defined problem from question 1, the aim is to explore whether the solution (the AI system) answers the question. In extreme cases, automatic theorem-proving systems can be used, but the apparent finality of formal mathematical proofs should not seduce one into a belief that the system is necessarily performing well. The importance of positive answers to all questions is illustrated by the cautionary comment from 2 to the effect that “formal proofs of an algorithm’s optimal quality do not guarantee that an application implements or uses the algorithm correctly, and thus software testing is necessary.
Validating AI algorithms is tougher than validating conventional algorithms because the former may have the capacity to adapt. Indeed, that is often the essence of such programs and is what provides the “intelligence” in “artificial intelligence” and the “learning” in “machine learning.” Sometimes this is described as meaning their behavior is “non-deterministic,” because it depends on external events or other changing circumstances and is not the least, random internal aspects, as with simulated annealing, genetic algorithms, and stochastic approximation. The adaptability of such systems and their flexibility in responding to external events can lead to a state space explosion.
Aspects of Validation
Question 1 is clearly very context-dependent, and there is little we can say about that, at least in a short space. The other questions, however, hinge on two main aspects: the data and the algorithm. let’s look at these aspects separately.
Data quality is a perennial issue for all quantitative disciplines, in particular including statistics, data mining, machine learning, and artificial intelligence. As various aphorisms (e.g., “bad data in, bad out”) attest, it is a truism that the validity of the results of an analysis depends on the quality of the input data. While it might be the case that a system works perfectly with perfect data, it is a brave assumption to suppose that the data the system encounters in practical application will always be perfect. Note that very large or rapidly streaming datasets cannot be checked by hand.
In general, while algorithms might be robust to some data quality issues, there will be others to which they are highly sensitive, and there will be breakdown points in terms of the extent of poor quality that can be handled. In some cases, such breakdown points involve only a tiny percentage of the data. It is also important to note that data might be perfectly fine for some purposes but poor for others, validation must be applied with the right objective in mind.
Data often arise from multiple sources, linked, merged, or otherwise combined by the AI, and the different datasets might have different degrees of quality and of compatibility. The validation exercise should explore these aspects. In addition to obvious data quality issues, there are challenges of non[1]stationary problems ‘so-called data set drift’ where the nature of the underlying dataset changes over time. Validation should consider the complete life cycle of the system. In general, the data to which a system is exposed during a validation exercise should span the entire space of scenarios the system is likely to encounter, insofar as this is possible. Statisticians have always cautioned about extrapolating beyond the data, but the autonomy of an AI system means it might well encounter novel situations.
Validation of the algorithms themselves means confirming that they solve the problem presented to them, really questions 2–5. apart from formal mathematical proofs, which can be used in limited circumstances, the most common strategy is to embed the AI in an artificial environment that generates simulated data of the kind it is likely to meet. Clearly, the efficacy of this depends on how well the simulated data reflect real data, complete with anomalous data points, etc. As we noted above, it is important to generate extreme cases and span the space of types of situations. This can be a challenge for AI systems because of the diversity of different scenarios they might encounter. The struggles to develop fully autonomous driverless vehicles have illustrated this. But even using real test data can run into problems. Real data have often undergone some prior selection procedure such that they may not properly represent the datasets that the AI will be dealing with.
There is an analogy to stress testing that plays a major role in validating a system, sensitivity analysis is another related idea.
In many situations, validation involves running the algorithm on cases where the “right” answer is known, to see whether, while the question might be properly formulated and the AI system might function as intended, it might simply not be very good. This sort of problem has been the focus of a vast amount of work with a wide variety of performance criteria being used. This abundance can conceal the importance of ensuring that an appropriate criterion is used. There is often also a trade-off between the robustness of a system, meaning it does not react wildly to slight changes of the data, and accuracy, meaning that it does not adapt sufficiently to changes in the data.
A common strategy used in validating (or, perhaps more appropriately, “evaluating”) such algorithms is a cross-validation or holdout strategy, in which available data are split into two sets: one to construct the algorithm, e.g., estimate parameters; and the other to test it. Note, however, that this assumes stationarity of the underlying dataset. In many real situations, future data are unlikely to be drawn from exactly the same distribution as the design data, so a misleading impression can be gained.
The point about including extreme cases in the validation exercise raises the question of whether an AI knows its limits. If sufficiently anomalous data arise, the system should recognize this and stop, rather than simply continue regardless. Think of an autonomous lawn mower stopping at the edge of the lawn.
Accelerating AI and Model Lifecycle Management
(Implement trustworthy AI)
Address explainability, fairness, robustness, transparency, and privacy as part of the AI lifecycle. Mitigate model drift, bias, and risk in AI and machine learning. Validate and monitor models to verify that AI and machine learning performance meets business goals. Meet regulation requirements in manufacturing drug products for the patient (i.e.; drug: safety, quality, efficacy, and purity). Help meet corporate social responsibility (CSR) and environmental social governance (ESG).
Increase Efficiency
Cut costs of AI and machine learning model operations through unifying tools, processes, and people. Reduce spend on managing legacy or point tools and infrastructures. Save time and resources to deliver production-ready models with automated AI and ML lifecycles. Also, should deliver data that is attributable, legible, contemporaneously recorded, original or a true copy, and accurate (ALCOA).
Automate Key Steps in the Model Lifecycle, Data Pre-Processing
Apply various algorithms, or estimators, to analyze, clean, and prepare raw data for machine learning. Automatically detect and categorize features based on data type, such as categorical or numerical. Use hyperparameter optimization to determine the best strategies for missing value imputation, feature encoding, and feature scaling.
Automated Model Selection
Select models through candidate algorithm testing and ranking against small subsets of the data. Gradually increase the size of the subset for the most promising algorithms. Enable ranking of a large number of candidate algorithms for model selection with the best match for the data.
Feature Engineering
Transform raw data into the combination of features that best represent the problem to achieve the most accurate prediction. Explore various feature construction choices in a structured, non-exhaustive manner, while progressively maximizing model accuracy using reinforcement learning.
Hyperparameter Optimization
Refine and optimize model pipelines using model training and scoring typical in machine learning. Choose the best model to put into production based on performance.
Model Monitoring Integration
Integrate monitoring of model drift, fairness, and quality through model input and output details, training data, and payload logging. Implement passive or active debiasing, while analyzing direct and indirect bias.
Model Validation Support
Extend with model and data insights and validate if your models meet your expected performance. Continuously improve your models by measuring model quality and comparing model performance, Figure 5.
Factory of the Future: How Industry 4.0 and AI Can Transform Manufacturing
New digital technologies can upgrade lean manufacturing, boost performance, and accelerate sustainability. Around the world, manufacturers have spent the past 50 years implementing a range of programs and techniques to reduce costs and improve product quality and customer service. Lean, total productive maintenance (TPM), total quality management (TQM), Six Sigma, and, in some cases, full production systems have yielded solid results. We’ve seen companies that leverage these approaches well, such as Toyota, Motorola, Procter & Gamble, and Danaher; boost productivity by 6% or more a year.
Those investments aren’t obsolete, but they also aren’t enough. To compete effectively in the future, you need to rethink what’s possible today.
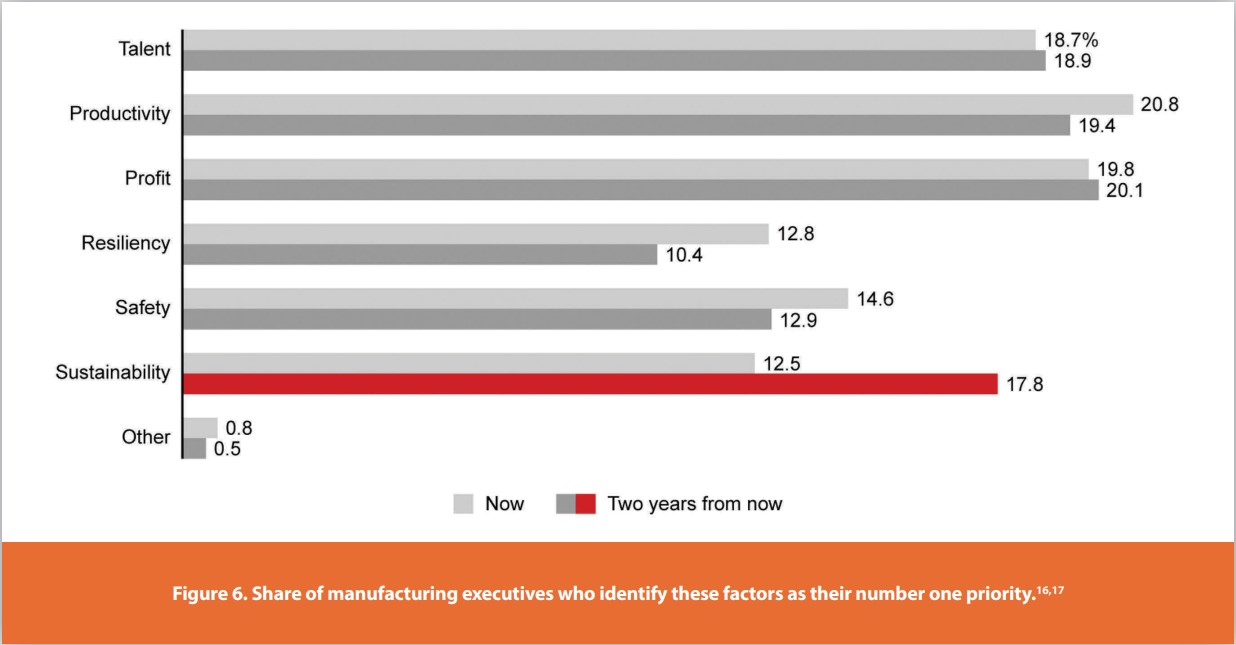
To cite just a few digital possibilities, artificial intelligence (AI) could, in essence, read a customer’s mind, predict demand, and steer products along individual paths through the supply chain, while production units become self-healing and self-learning, freeing humans to focus on creative tasks and supervision. The many benefits of digital aren’t lost on leading companies. In a recent survey of 270 manufacturing executives around the world, respondents who say digital is well-integrated into their production systems are three times as likely to say they’re close to achieving their production system goals, compared with those who lack high levels of integration, Figure 6.16,17
Future of Technology in Manufacturing
By 2030, Industry 4.0, AI, and advanced materials will disrupt the entire manufacturing value chain by enabling digital factories and smart supply chains. The future of manufacturing lies with innovative modalities like synthetic biology (SynBio). By 2030, innovative technologies will be at the heart of the bioeconomy and will have unlocked a range of new products and concepts through new biological systems or re-designing existing ones for useful purposes, Figure 7.
References
- T. Menzies, C. Pecheur, Verifi cation and Validation and Artifi cial Intelligence, Adv. Comput., 65 (2005), pp. 153-201
- X. Xie, J.W.K. Ho, C. Murphy, G. Kaiser, B. Xu, T.Y. Chen, Testing and validating machine learning classifiers by metamorphic testing, J. Syst. Softw., 84 (2011), pp. 544-558; Testing and validating machine learning classifiers by metamorphic testing - ScienceDirect
- E. Breck, N. Polyzotis, S. Roy, S.E. Whang, M. Zinkevish, Data validation for machine learning. Proceedings of the 2nd SysML Conference, https://mlsys.org/Conferences/2019/ doc/2019/167.pdf (2019)
- D. Karmon, D. Zoran, Y. Goldberg, LaVAN: Localized and Visible Adversarial Noise, arXiv (2018), 1801.02608, https://arxiv.org/abs/1801.02608
- BoE, https://www.bankofengland.co.uk/stress-testing (2020)
- D.J. Hand, Assessing the performance of classification methods, Int. Stat. Rev., 80 (2012), pp. 400-414
- S. Wachter, B. Mittelstadt, L. Floridi; Why a Right to Explanation of Automated Decision-Making Does Not Exist in the General Data Protection Regulation, Int. Data Privacy Law (2017), 10.2139/ssrn.2903469
- Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) - Discussion Paper and Request for Feedback, 2019; US FDA Artificial Intelligence and Machine Learning Discussion Paper
- ISPE GAMP 5: A Risk-based Approach to Compliant GxP Computerized Systems, Second Edition, Handbook / Manual / Guide by International Society for Pharmaceutical Engineering, 07/31/2022; ISPE GAMP 5: A Risk-Based Approach to Compliant GxP Computerized Systems, Second Edition (techstreet.com).
- Guidance Document, Part 11, Electronic Records; Electronic Signatures - Scope and Application, Guidance for Industry, September 2003, Guidance for Industry - Part 11, Electronic Records; Electronic Signatures — Scope and Application (fda.gov)
- EudraLex The Rules Governing Medicinal Products in the European Union Volume 4 Good Manufacturing Practice Medicinal Products for Human and Veterinary Use Annex 11: Computerised Systems, 30 June 2011; Annex 11 Final 0910 (europa.eu)
- Artificial Intelligence and Machine Learning (AI/ML) Software as a Medical Device Action Plan, 09/22/2021; https://www.fda.gov/medical-devices/software-medical-device-samd/artifi cial-intelligence-and-machine-learning-software-medical-device
- Evolving Michelangelo Model Representation for Flexibility at Scale, October 16, 2019 / Global; Evolving Michelangelo Model Representation for Flexibility at Scale | Uber Blog
- Trenton Systems Blog, What is Deep Learning (DL), Christopher Trick, on Apr 21, 2022, What is Deep Learning (DL)? (trentonsystems.com)
- Accelerating AI and model lifecycle management; AutoML and AutoAI - IBM Watson Studio | IBM
- Jörg Gnamm, Thomas Frost, Frank Lesmeister, and Christian Ruehl, Factory of the Future: How Industry 4.0 and AI Can Transform Manufacturing; New digital technologies can upgrade lean manufacturing, boosting performance and accelerating sustainability, Bain & Company, July 10, 2023; https://www.bain.com/insights/factory-of-the-future-how-industry-4-0-and-ai-can-transform-manufacturing/
- Robert Dream, The Factory of the Future, March 24, 2022; The Factory of the Future | American Pharmaceutical Review - The Review of American Pharmaceutical Business & Technology
Publication Detail
This article appeared in American Pharmaceutical Review:Vol. 27, No. 1Jan/FebPages: 18-25
Subscribe to our e-Newsletters
Stay up to date with the latest news, articles, and events. Plus, get special
offers from American Pharmaceutical Review delivered to your inbox!
Sign up now!