Gene therapy has emerged as a promising therapeutic for the treatment of genetic and acquired diseases. Gene transfection into target cells using naked DNA is a simple and safe approach that has been further improved by combining vectors or gene carriers. Both viral and non-viral approaches have achieved a milestone to establish this technique, but non-viral approaches have attained significant attention because of their favorable properties like less immunotoxicity and biosafety, and are easy to produce with versatile surface modifications. Literature reveals that non–viral vectors have acquired a unique place in gene therapy. However, still, there are a number of challenges that need to be overcome to increase their effectiveness and prove them ideal gene vectors, Figure 1.
Various non-viral vectors can be used to deliver DNA, mRNA, and short double-stranded RNA, including small interfering RNA (siRNA) and microRNA (miRNA) mimics. These vectors need to prevent degradation by serum endonucleases and evade immune detection (which could be achieved by chemical modifications of nucleic acids and encapsulation of vectors).
Somatic Cells
Somatic cells are any cells in the body that are not gametes (sperm or egg), germ cells (cells that go on to become gametes), or stem cells. Essentially, all cells that make up an organism’s body and are not used to directly form a new organism during reproduction are somatic cells. The word somatic comes from the Greek word σώμα (soma), which means body. In the human body, there are about 220 types of somatic cells.
Germ Line
In sexually reproducing organisms, cells of the germ line form gametes and establish a physical link, an unbroken chain, from generation to generation.
In biology and genetics, the germline is the population of a multicellular organism’s cells that develop into germ cells. In other words, they are the cells that form gametes (eggs and sperm), which can come together to form a zygote. They differentiate in the gonads from primordial germ cells into gametogonia, which develop into gametocytes, which develop into the final gametes. This process is known as gametogenesis.
Germ cells pass on genetic material through the process of sexual reproduction. This includes fertilization, recombination, and meiosis. These processes help to increase genetic diversity in offspring.
What is Gene Therapy?
Human gene therapy seeks to modify or manipulate the expression of a gene or to alter the biological properties of living cells for therapeutic use.50
Gene therapy is a technique that modifies a person’s genes to treat or cure disease. Gene therapies can work by several mechanisms, Table 1:
- Replacing a disease-causing gene with a healthy copy of the gene.
- Inactivating a disease-causing gene that is not functioning properly.
- Introducing a new or modified gene into the body to help treat a disease.
Gene therapy products are being studied to treat diseases including cancer, genetic diseases, and infectious diseases.
There are a variety of types of gene therapy products, including:
- Plasmid DNA: Circular DNA molecules can be genetically engineered to carry therapeutic genes into human cells.
- Viral vectors: Viruses have a natural ability to deliver genetic material into cells, and therefore some gene therapy products are derived from viruses. Once viruses have been modified to remove their ability to cause infectious disease, these modified viruses can be used as vectors (vehicles) to carry therapeutic genes into human cells.
- Bacterial vectors: Bacteria can be modified to prevent them from causing infectious disease and then used as vectors (vehicles) to carry therapeutic genes into human tissues.
- Human gene editing technology: The goals of gene editing are to disrupt harmful genes or to repair mutated genes.
- Patient-derived cellular gene therapy products: Cells are removed from the patient, genetically modified (often using a viral vector), and then returned to the patient.
1. Viral Vectors
a. Viral vectors are derived from viruses and are commonly used in gene therapy.
b. They are highly effective at delivering genetic material into cells due to their natural ability to infect and integrate their genetic cargo.
c. Examples of viral vectors include adenoviruses, lentiviruses, and adeno-associated viruses (AAVs), see Table 2.
d. However, there are some limitations associated with viral vectors:
- Immunogenicity: Viral vectors can trigger immune responses in the body, potentially leading to adverse effects.
- Oncogenicity: Some viral vectors may carry a risk of causing cancer.
- DNA Size Limit: Viral vectors have constraints on the size of DNA they can carry.
e. Despite these limitations, viral vectors remain widely used in clinical trials and gene therapy products.48
2. Non-viral Vectors
a. Non-viral vectors do not originate from viruses. Instead, they are synthetic or naturally occurring carriers for delivering genetic material.
b. Advantages of non-viral vectors include:
- Safety: They are generally safer than viral vectors, with lower cytotoxicity, immunogenicity, and mutagenesis.
- Cost-effectiveness: Non-viral vectors are easier and cheaper to produce.
- No DNA Size Limit: Unlike viral vectors, non-viral vectors do not have strict size limitations for the DNA they can transport.
c. Types of non-viral vectors include Table 2:
- Polymers: Synthetic polymers that can encapsulate DNA.
- Lipids: Lipid nanoparticles (LNPs) are commonly used for RNA-based therapies.
- Inorganic Particles: Examples include gold nanoparticles.
d. Non-viral vectors are actively researched, and ongoing studies aim to improve their efficiency, specificity, and safety.49,50
RNA-based therapy is a promising and potential strategy for disease treatment by introducing exogenous nucleic acids such as messenger RNA (mRNA), small interfering RNA (siRNA), microRNA (miRNA), or antisense oligonucleotides (ASO) to modulate gene expression in specific cells. It is exciting that mRNA encoding the spike protein of COVID-19 (coronavirus disease 2019) delivered by lipid nanoparticles (LNPs) exhibits the efficient protection of lung infection against the virus, as in examples in Figures 2, 3, and 4.
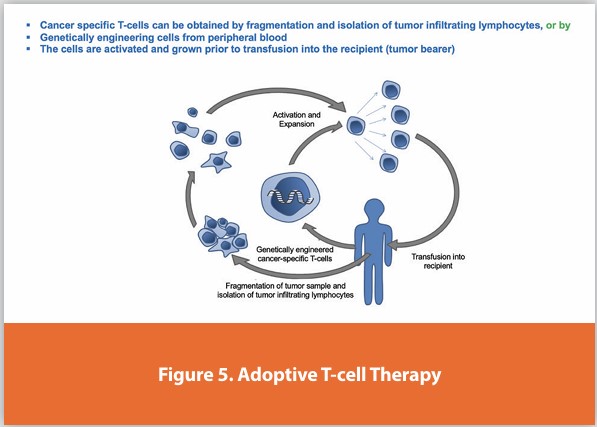
Adoptive Cell Transfer (ACT)
Adoptive cell transfer (ACT) is the transfer of cells into a patient. The cells may have originated from the patient or another individual. The cells are most commonly derived from the immune system to improve immune functionality and characteristics. In autologous cancer immunotherapy, T-cells are extracted from the patient, genetically modified and cultured in vitro, and returned to the same patient. Comparatively, allogeneic therapies involve cells isolated and expanded from a donor separate from the patient receiving the cells.
Cancer-specific T-cells can be obtained by fragmentation and isolation of tumor infiltrating lymphocytes, or by genetically engineered cells from peripheral blood. The cells are activated and grown prior to transfusion into the recipient (tumor bearer), Figure 5.
Polyethylenimine (PEI) or polyaziridine is a polymer with repeating units composed of the amine group and two carbon aliphatic CH2 CH2 spacers. Linear polyethyleneimines contain all secondary amines, in contrast to branched PEIs which contain primary, secondary, and tertiary amino groups. Branched, dendrimeric forms were also reported. PEI is produced on an industrial scale and finds many applications usually derived from its polycationic character.
Transfection Reagents
Poly(ethylenimine) was the second polymeric transfection agent discovered, after poly-L-lysine. PEI condenses DNA into positively charged particles, which bind to anionic cell surface residues and are brought into the cell via endocytosis. Once inside the cell, protonation of the amines results in an influx of counter-ions and a lowering of the osmotic potential. Osmotic swelling results and bursts the vesicle releasing the polymer-DNA complex (polyplex) into the cytoplasm. If the polyplex unpacks then the DNA is free to diffuse to the nucleus.
Oligonucleotides
Oligonucleotides are short DNA or RNA molecules, oligomers, that have a wide range of applications in genetic testing, research, and forensics. Commonly made in the laboratory by solid-phase chemical synthesis, these small bits of nucleic acids can be manufactured as single-stranded molecules with any user-specified sequence, and so are vital for artificial gene synthesis, polymerase chain reaction (PCR), DNA sequencing, library construction, and as molecular probes. In nature, oligonucleotides are usually found as small RNA molecules that function in the regulation of gene expression (e.g. microRNA) or are degradation intermediates derived from the breakdown of larger nucleic acid molecules.
Oligonucleotides are characterized by the sequence of nucleotide residues that make up the entire molecule. The length of the oligonucleotide is usually denoted by “-mer” (from Greek meros, “part”). For example, an oligonucleotide of six nucleotides (nt) is a hexamer, while one of 25 nt would usually be called a “25-mer”. Oligonucleotides readily bind, in a sequence-specific manner, to their respective complementary oligonucleotides, DNA, or RNA to form duplexes or, less often, hybrids of a higher order. This basic property serves as a foundation for the use of oligonucleotides as probes for detecting DNA or RNA. Examples of procedures that use oligonucleotides include DNA microarrays, Southern blots, ASO analysis, fluorescent in situ hybridization (FISH), PCR, and the synthesis of artificial genes.
Oligonucleotides composed of 2’-deoxyribonucleotides (oligo-deoxy ribonucleotides) are fragments of DNA and are often used in the polymerase chain reaction, a procedure that can greatly amplify almost any small amount of DNA. There, the oligonucleotide is referred to as a primer, allowing DNA polymerase to extend the oligonucleotide and replicate the complementary strand.
There are an increasing number of applications that have been developed for oligonucleotide-based biosensing systems in genetics and biomedicine. Oligonucleotide-based biosensors are those where the probe to capture the analyte is a strand of deoxyribonucleic acid (DNA), ribonucleic acid (RNA), or a synthetic analog of naturally occurring nucleic acids. DNA/RNA aptamers can be used as bioreceptors for a wide range of targets such as proteins, small molecules, bacteria, and even cells. Highlighting how the invention of synthetic oligonucleotides such as Peptide Nucleic Acid (PNA) or Locked Nucleic Acid (LNA) has pushed the limits of molecular biology and biosensor development to new perspectives. These technologies are very promising, but still in need of development to bridge the gap between the laboratory-based status and the reality of the applications of biomedicine.

Oligonucleotides are unmodified or chemically modified polymers (DNA or RNA) that are relatively small (12–25-mer) and introduce an expanded range of applications in molecular genetics research and forensics. In the natural world, oligonucleotides exist mainly as small non-coding RNAs (e.g. microRNAs (miRNAs)). Such oligonucleotides are commonly synthesized using solid-phase chemistry. Chemical modifications of the sugar-phosphate backbone or the bases are often used to increase the stability and half-life of oligonucleotides. In general, oligonucleotides work by hybridizing to their complementary sequences. They are used in many different ways including as ‘primers’ in polymerase chain reaction (PCR), as ‘probes’ in microarray analysis or situ hybridization, and in biosensing applications. The explosion of knowledge regarding gene expression and gene regulation mechanisms has led to many new opportunities to develop oligonucleotide-based technologies.
Chromatin, Transcription and Post-Transcriptional Regulation
The regulation of transcription is a fundamental aspect of gene regulation. To be expressed, genes need to be transcribed, producing either a messenger RNA (mRNA) or a non-coding RNA. Promoters and distal enhancer sequences facilitate the recruitment of RNA polymerases and the process of transcription, in which DNA is unwound and one strand copied into a complementary RNA transcript, begins at discrete start sites in the genome. In vivo DNA does not exist in a ‘naked’ state; instead, it is packaged by proteins into structures called nucleosomes by proteins called histones. DNA that is packaged by proteins such as histones (or by protamines in sperm cells) is called chromatin. For transcription to occur, the chromatin structure often needs to be loosened in a process called chromatin remodeling. This remodeling occurs following the covalent modification of histones by enzymes including histone acetyltransferases, deacetylases, protein kinases, and methyltransferases. DNA can also be modified directly at CpG (a cytosine followed by a guanine nucleotide) positions by the methylation of cytosine to 5-methylcytosine. Methylated DNA tends to be associated with genes that are less transcriptionally active. Chromatin remodeling and DNA modifications, both in response to physiological, developmental, and environmental cues, do not alter the actual base sequence of DNA.1 However, they do reversibly alter gene expression in a process called epigenetics (‘epi’ is from the Greek for ‘outside of’).
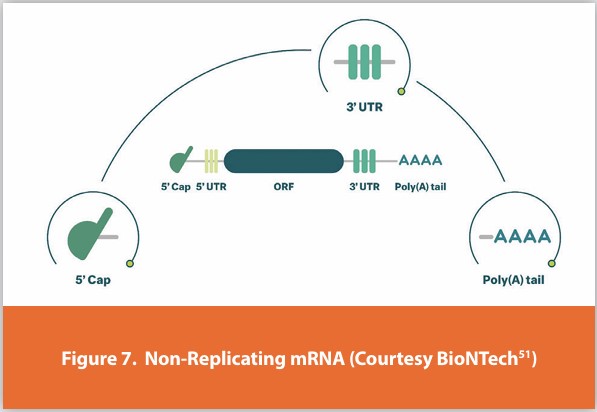
The products of transcription, in other words, RNA molecules, are called transcripts; in general, transcripts need to be processed. The precursor of mRNA, pre-mRNA, needs to be modified at the 5’ end, Figure 7.
This consists of a series of covalent modifications to the first base (the so-called trimethyl m7G cap). The 5’ cap facilitates nuclear export, mRNA translation, and mRNA stability. Pre-mRNA is also cleaved at the 3’ end (defining the end of the transcript) and polyadenylated. Further complexity arises from the process of pre-mRNA splicing, discovered in the late 1970s. In pre-mRNA splicing, sequences known as introns are precisely removed (spliced) and exons are joined together to form the mature mRNA. Collectively, capping, splicing, cleavage, and polyadenylation are known as pre-mRNA processing. They mostly occur co-transcriptionally, i.e. while the RNA polymerase is still working its way along the gene. The C-terminus of RNA polymerase II can recruit pre-mRNA processing factors through its heavily phosphorylated C-terminal domain (CTD). The process, called alternative splicing, in which exons are joined together in different ways, results in several transcripts with potentially different coding potentials.
Several other regulatory processes occur. RNA editing involves the direct chemical modification of RNA bases (e.g. adenine to inosine) potentially altering coding potential. mRNA export is a regulated process; incorrectly processed mRNAs are retained in the nucleus. In the cytoplasm, mRNA translation, mRNA localization, and mRNA stability are all highly regulated. Localization allows mRNAs to be delivered to and translated into discrete parts of the cytoplasm where the protein is needed, such as an axon or lamellipodia. Translation consists of three steps, initiation, elongation, and termination, each of which is highly regulated. The extent to which an mRNA is translated affects how much protein is made. Further complexity arises from the presence of occasional alternative translation start codons. mRNAs have a half-life; some are more stable than others and an mRNA’s half-life has a bearing on how much protein is made. Degradation of mRNA is also highly regulated in response to developmental and physiological cues.
Alternative Splicing of Pre-mRNA
One gene, multiple transcripts; when pre-mRNA splicing was first observed in eukaryotic viruses, the discoverers had no idea that over 94% of human genes would turn out to be alternatively spliced.3,4 Alternative splicing is the process whereby exons are not always joined together in the same way. The main types of alternative splicing are intron retention (sometimes introns are not spliced out), cassette exons; exons can be skipped entirely, and alternative 5’ and 3’ splice sites, in which the boundaries of the exons can change. Through alternative splicing, genes can express dozens of splice isoforms. Genes can even produce thousands of transcripts; a famous example is the fruit fly Dscam gene.5 The effect of alternative splicing to augment the size of the proteome is very significant. Splice isoforms often have antagonistic functions and their expression is regulated by proteins called splice factors. In the biosensing field, the existence of multiple, often biologically distinct, splice isoforms provides the opportunity to develop ways to detect and measure levels of specific splice isoforms.
DNA Aptamers
An emerging class of protein-binding oligonucleotides is aptamers. These are single-stranded DNA or RNA sequences that are deliberately designed to bind to a particular molecule (including proteins) with high specificity and affinity. They are considered alternatives to antibodies, where they can bind to their targets by undergoing conformational changes.15 An aptamer for a specific target is derived through selective rounds of binding followed by amplification using the technique known as SELEX (systematic evolution of ligands by exponential enrichment). SELEX has been used to determine which DNA or RNA species are bound by proteins of interest. One of the most studied DNA aptamers was raised against the protein thrombin. Thrombin forms a signature quadruplex structure by capturing the protein. The thrombin protein is ‘trapped’ within the structure and therein it stabilizes.
Aptamers have many advantages over antibodies making them very important molecular tools for both diagnostics and therapeutics. There has been an intense interest in the in-depth understanding of ligand binding and conformational properties. This has led to a range of bioassay methods that rely on aptamers as bioreceptors. Aptamers are currently used in drug-delivery applications along with a new emerging application as bioreceptors in bioassays and biosensors (termed aptasensors) aptasensors, employ nucleic acid aptamers as bio receptors for the recognition of target pathogens of interest. Aptamers can be used in different methodologies such as electrochemical, optical, or mass-sensitive.16,17 Aptamers have many advantages over antibodies, but they still face some challenges relating to nuclease degradation or reduced binding efficiency because of DNA/RNA binding proteins in the blood.
Artificial Oligonucleotide Analogues
There are many fields in biology which has the potential to use synthetic oligonucleotides. The reason for such a turnover is mainly due to the emergence of different molecular cloning techniques along with the simultaneous development of varied methods for efficient oligonucleotide synthesis. The primary motivations behind these developments for biochemists have been not only the huge biological potential but also the immense demand for synthetic oligonucleotides. Synthetic oligonucleotides or nucleic acid analogs are compounds that are structurally similar to naturally occurring RNA or DNA. Some of the artificial nucleic acids include peptide nucleic acid (PNA), locked nucleic acid (LNA), glycol nucleic acid (GNA), and threose nucleic acid (TNA), which differ from naturally occurring RNA or DNA in the backbone structure of the molecule. Consequently, the availability of these synthetic oligonucleotides has led to a revolution in solving molecular biology problems along with promising applications in biosensing.
Peptide Nucleic Acids
Peptide nucleic acid (PNA) was first invented by Nielsen et al. in 1991.18 PNA is a DNA analog where the sugar-phosphate backbone of DNA is replaced by a backbone comprising of repeated units of N-(2 aminoethyl)glycine units via an amide linkage. Such a modification changes the negative charges of the DNA sugar-phosphate backbone to a neutral charge of the peptide-like backbone. In a PNA, the four naturally occurring nucleobases, namely adenine, cytosine, guanine, and thymine, are connected to the central amine of the peptide backbone via a methylene bridge and a carbonyl group. Therefore, PNA sequences are depicted like any peptide with an N-terminus at the left end position and a C-terminus at the right end position.
Since PNA has a neutral charge and proper Interbase spacing, PNA can bind to its complementary DNA sequence with higher affinity and specificity following the rules of Watson–Crick base pairing.19 This is because of the reduced electrostatic repulsion between PNA and DNA compared with DNA and DNA. It also results in reduced melting temperatures of the PNA–DNA duplex leading to higher thermal stability. Moreover, it has also been demonstrated that the stability of a PNA–DNA duplex is essentially independent of the ionic strength of the buffer in which hybridization is performed.20
Because of its unique physico-chemical and biochemical properties, PNA as a bioreceptor opens up many applications (biological and diagnostic) that would not be achievable with naturally occurring oligonucleotides. Many reports in the literature show how PNA has been exploited to detect miRNAs/DNA in biological samples. A range of electrochemical techniques have been successfully applied for PNA-based biosensing.21-22 For example, Keighley et al.22 demonstrate how the neutral charge of PNA can be exploited with electrochemical impedance spectroscopy: whereas DNA probes on an electrode offer high resistance to negatively charged redox markers in solution,23 neutral PNA probes do not; upon binding with the complementary strand, a massive increase in resistance was observed because of the addition of negative charges and increased binding efficiency compared with DNA–DNA.
Locked Nucleic Acids
Locked nucleic acids (LNAs) are another class of synthetic nucleotides which is often referred to as inaccessible RNA. LNA was first synthesized by both Obika et al.24 and Koshkin et al.25 in 1997. It consists of a modified RNA nucleotide, where the ribose moiety is modified with an extra bridge that connects the 2’ oxygen and 4’ carbon. Such a linkage via a methylene bridge restricts (locks) the ribofuranose into the 3’-endo conformation, which is responsible for LNA–DNA or LNA RNA heteroduplexes.26 LNA nucleotides can be easily mixed with DNA or RNA molecules in the oligonucleotide sequence, which greatly improves the thermal stability of LNA–DNA or LNA–miRNA duplexes. LNA, like DNA, forms specific base pairing with complementary DNA/ RNA sequences following Watson–Crick rules. By introducing LNA molecules, the melting temperature can be increased by 2.0–6.0°C per LNA monomer for an LNA–DNA duplex and 3.0–9.6°C for an LNA–RNA duplex.27 It has been reported that LNA forms the strongest duplexes with RNAs which has opened new doors for miRNA technology along with DNA detection28 and biosensors.
LNA has been used as a probe for microarray technology for the detection of multiple miRNAs via a novel approach, achieving limits of detection in the attomolar range.29 This novel approach where the enzyme reaction is combined with nanoparticle amplification using surface plasmon resonance (SPR) as a detection technique. A poly(A) polymerase was used to extend the miRNAs bound to LNA on the surface with a poly(A) tail. Later, gold nanoparticles modified with poly(T) tails were hybridized with the poly(A) tail which could then be detected using SPR.
Although PNA and LNA have been shown to have many advantages over naturally occurring DNA or RNA, they still suffer from limitations that include the constraints with the length of the sequence and composition of bases that can affect the stability of PNA or LNA. This is one of the main reasons PNA- or LNA-based microarrays are currently not used as high-throughput biosensors. Nonetheless, biosensors based on artificial analogs are still in the early stage of development, and exciting new developments are expected as these become more mature.
Glycol Nucleic Acid
Glycol nucleic acid (GNA), sometimes also referred to as glycerol nucleic acid, is a nucleic acid similar to DNA or RNA but differing in the composition of its sugar-phosphodiester backbone, using propylene glycol in place of ribose or deoxyribose.1 GNA is chemically stable but not known to occur naturally. However, due to its simplicity, it might have played a role in the evolution of life.
The 2,3-dihydroxypropyl nucleoside analogs were first prepared by Ueda et al. (1971). Soon thereafter it was shown that phosphate-linked oligomers of the analogues do exhibit hypochromicity in the presence of RNA and DNA in solution (Seita et al. 1972). The preparation of the polymers was later described by Cook et al. (1995, 1999) and Acevedo and Andrews (1996). However, the ability of GNA GNA self-pairing was first reported by Zhang and Meggers in 2005 [30]. Crystal structures of a GNA duplex were subsequently reported by Essen and Meggers.31,32
DNA and RNA have a deoxyribose and ribose sugar backbone, respectively, whereas GNA’s backbone is composed of repeating glycol units linked by phosphodiester bonds. The glycol unit has just three carbon atoms and still shows Watson–Crick base pairing. The Watson–Crick base pairing is much more stable in GNA than its natural counterparts DNA and RNA as it requires a high temperature to melt a duplex of GNA. It is possibly the simplest of the nucleic acids, making it a hypothetical precursor to RNA.
Threose Nucleic Acid
Threose Nucleic Acid (TNA) is an artificial genetic polymer in which the natural five-carbon ribose sugar found in RNA has been replaced by an unnatural four-carbon threose sugar.33 Invented by Albert Eschenmoser as part of his quest to explore the chemical etiology of RNA,34 TNA has become an important synthetic genetic polymer (XNA) due to its ability to efficiently base pair with complementary sequences of DNA and RNA.33 The main difference between TNA and DNA/RNA is their backbones. DNA and RNA have their phosphate backbones attached to the 5’ carbon of the deoxyribose or ribose sugar ring, respectively. TNA, on the other hand, has its phosphate backbone directly attached to the 3’ carbon in the ring, since it does not have a 5’ carbon. This modified backbone35 makes TNA, unlike DNA and RNA, completely refractory to nuclease digestion, making it a promising nucleic acid analog for therapeutic and diagnostic applications.36
TNA oligonucleotides were first constructed by automated solid-phase synthesis using phosphoramidite chemistry. Methods for chemically synthesized TNA monomers (phosphoramidites and nucleoside triphosphates) have been heavily optimized to support synthetic biology projects aimed at advancing TNA research.37 More recently, polymerase engineering efforts have identified TNA polymerases that can copy genetic information back and forth between DNA and TNA.38,39 TNA replication occurs through a process that mimics RNA replication. In these systems, TNA is reverse transcribed into DNA, the DNA is amplified by the polymerase chain reaction, and then forward transcribed back into TNA.
The availability of TNA polymerases has enabled the in vitro selection of biologically stable TNA aptamers to both small molecule and protein targets.40-42 Such experiments demonstrate that the properties of heredity and evolution are not limited to the natural genetic polymers of DNA and RNA.43 The high biological stability of TNA relative to other nucleic acid systems that are capable of undergoing Darwinian evolution, suggests that TNA is a strong candidate for the development of next-generation therapeutic aptamers.
The mechanism of TNA synthesis by a laboratory-evolved TNA polymerase has been studied using X-ray crystallography to capture the five major steps of nucleotide addition.44 These structures demonstrate imperfect recognition of the incoming TNA nucleotide triphosphate and support the need for further directed evolution experiments to create TNA polymerases with improved activity. The binary structure of a TNA reverse transcriptase has also been solved by X-ray crystallography, revealing the importance of structural plasticity as a possible mechanism for template recognition.45
Pre-DNA system John Chaput, a professor in the Department of Pharmaceutical Sciences at the University of California, Irvine, has theorized that issues concerning the prebiotic synthesis of ribose sugars and the non-enzymatic replication of RNA may provide circumstantial evidence of an earlier genetic system more readily produced under primitive earth conditions. {{subst:cn}} TNA could have been an early genetic system and a precursor to RNA.46 TNA is simpler than RNA and can be synthesized from a single starting material. TNA can transfer back and forth information with RNA and with strands of itself that are complementary to the RNA. TNA has been shown to fold into tertiary structures with discrete ligand-binding properties.40
Commercial applications Although TNA research is still in its infancy, practical applications are already apparent. Its ability to undergo Darwinian evolution, coupled with its nuclease resistance, makes TNA a promising candidate for the development of diagnostic and therapeutic applications that require high biological stability. This would include the evolution of TNA aptamers that can bind to specific small molecule and protein targets, as well as the development of TNA enzymes (threozymes) that can catalyze a chemical reaction. In addition, TNA is a promising candidate for RNA therapeutics that involve gene silencing technology. For example, TNA has been evaluated in a model system for antisense technology.47
Antisense Oligonucleotides
Antisense oligonucleotides are synthetic polymers in which some or all of the natural nucleotide monomers of the oligonucleotide are chemically modified deoxynucleotides (in DNA) or ribonucleotides (in RNA). Normally, antisense oligonucleotides contain 15 to 25 monomers. In antisense technology, single-stranded DNA or RNA molecules are used to target a specific sense mRNA. Antisense compounds have become effective tools for basic molecular biology, genomics, and proteomics research, which is often used for drug discovery, targeted screening, and validation. For example, antisense oligonucleotides can act by blocking the upstream message for receptor substrates, proteins over-expressed in pathological versus physiological states.
References
- Castelnuovo M., Stutz F. Role of chromatin, environmental changes and single cell heterogeneity in non-coding transcription and gene regulation. Curr. Opin. Cell Biol. 2015;34:16–22. doi: 10.1016/j.ceb.2015.04.011. [PubMed] [CrossRef] [Google Scholar]
- Lin K., Gregory R.I. MicroRNA biogenesis pathways in cancer. Nat. Rev. Cancer. 2015;15:321–333. doi: 10.1038/nrc3932. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Hallegger M., Llorian M., Smith C.W. Alternative splicing: global insights. FEBS J. 2010;277:856–866. doi: 10.1111/j.1742-4658.2009.07521.x. [PubMed] [CrossRef] [Google Scholar]
- Jangi M., Sharp P.A. Building robust transcriptomes with master splicing factors. Cell. 2014;159:487–498. doi: 10.1016/j.cell.2014.09.054. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Celotto A.M., Graveley B.R. Alternative splicing of the Drosophila Dscam pre-mRNA is both temporally and spatially regulated. Genetics. 2001;159:599–608. [PMC free article] [PubMed] [Google Scholar]
- Mitra D., Brumlik M.J., Okamgba S.U., Zhu Y., Duplessis T.T., Parvani J.G., et al. An oncogenic isoform of HER2 associated with locally disseminated breast cancer and trastuzumab resistance. Mol. Cancer Ther. 2009;8:2152–2162. doi: 10.1158/1535-7163.MCT-09-0295. [PubMed] [CrossRef] [Google Scholar]
- Zammarchi F., De Stanchina E., Bournazou E., Supakorndej T., Amrtires K., Riedel E., et al. The antitumorigenic potential of STAT3 alternative splicing modulation. Proc. Natl. Acad. U.S.A. 2011;108:17779–17784. doi: 10.1073/pnas.1108482108. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Frith M.C., Pheasant M., Mattick J.S. The amazing complexity of the human transcriptome. Eur. J. Hum. Genet. 2005;13:894–897. doi: 10.1038/sj.ejhg.5201459. [PubMed] [CrossRef] [Google Scholar]
- Djebali S., Davis C.A., Merkel A., Dobin A., Lassmann T., Mortazavi A., et al. Landscape of transcription in human cells. Nature. 2012;489:101–109. doi: 10.1038/nature11233. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Hangauer M.J., Vaughn I.W., McManus M.T. Pervasive transcription of the human genome produces thousands of previously unidentified long intergenic non-coding RNAs. PLoS Genet. 2013;9:e1003569. doi: 10.1371/journal.pgen.1003569. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Lee J.T. Lessons from X-chromosome inactivation: long ncRNA as guides and tethers to the epigenome. Genes Dev. 2009;23:1831–1842. doi: 10.1101/gad.1811209. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Kohlmaier A., Savarese F., Lachner M., Martens J., Jenuwin T., Wutz A. A chromosomal memory triggered by Xist regulates histone methylation in X inactivation. PLoS Biol. 2004;2:e171. doi: 10.1371/journal.pbio.0020171. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Londin E., Loher P., Telonis A.G., Quann K., Clark P., Jing Y., et al. Analysis of 13 cell types reveals evidence for the expression of numerous novel primate- and tissue-specific microRNAs. Proc. Natl. Acad. Sci. U.S.A. 2015;112:E1106–E1115. doi: 10.1073/ pnas.1420955112. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Giovannelli I., Martelli F., Repice A., Massacesi L., Azzi A., Giannecchini S. Detection of JCPyV microRNA in blood and urine samples of multiple sclerosis patients under natalizumab therapy. J. Neurovirol. 2015;21:666–670. [PubMed] [Google Scholar]
- Nimjee S.M., Rusconi C.P., Sullenger B.A. Aptamers: an emerging class of therapeutics. Annu. Rev. Med. 2005;56:555–583. doi: 10.1146/annurev.med.56.062904.144915. [PubMed] [CrossRef] [Google Scholar]
- Song S., Wang L., Li J., Fan C., Zhao J. Aptamer-based biosensors. Trends Anal. Chem. 2008;27:108–117. doi: 10.1016/j.trac.2007.12.004. [CrossRef] [Google Scholar]
- Jolly P., Formisano N., Estrela P. DNA aptamer-based detection of prostate cancer. Chem. Pap. 2015;69:77–89. doi: 10.1515/chempap-2015-0025. [CrossRef] [Google Scholar]
- Nielsen P.E., Egholm M., Berg R.H., Buchardt O. Sequence-selective recognition of DNA by strand displacement with a thymine-substituted polyamide. Science. 1991;254:1497 1500. doi: 10.1126/science.1962210. [PubMed] [CrossRef] [Google Scholar]
- Egholm M., Buchardt O., Christensen L., Behrens C., Freier S.M., Driver D.A., et al. PNA hybridizes to complementary oligonucleotides obeying the Watson–Crick hydrogen bonding rules. Nature. 1993;365:566–568. doi: 10.1038/365566a0. [PubMed] [CrossRef] [Google Scholar]
- Wang J. DNA biosensors based on peptide nucleic acid (PNA) recognition layers. A review. Biosens. Bioelectron. 1998;13:757–762. doi: 10.1016/S0956-5663(98)00039-6. [PubMed] [CrossRef] [Google Scholar]
- Wang J. From DNA biosensors to gene chips. Nucleic Acids Res. 2000;28:3011–3016. doi: 10.1093/nar/28.16.3011. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Keighley S.D., Li P., Estrela P., Migliorato P. Optimization of label-free DNA detection with electrochemical impedance spectroscopy using PNA probes. Biosens. Bioelectron. 2008;24:912–917. doi: 10.1016/j.bios.2008.07.041. [PubMed] [CrossRef] [Google Scholar]
- Keighley S.D., Li P., Estrela P., Migliorato P. Optimization of DNA immobilization on gold electrodes for label-free detection by electrochemical impedance spectroscopy. Biosens. Bioelectron. 2008;23:1291–1297. doi: 10.1016/j.bios.2007.11.012. [PubMed] [CrossRef] [Google Scholar]
- Obika S., Nanbu D., Hari Y., Morio K-I, In Y., Ishida T., Imanishi T. Synthesis of 2’-O,4’-C methyleneuridine and -cytidine. Novel bicyclic nucleosides having a fixed C3, -endo sugar puckering. Tetrahedron. Lett. 1997;38:8735–8738. doi: 10.1016/S0040-4039(97)10322-7. [CrossRef] [Google Scholar]
- Koshkin A.A., Rajwanshi V.K., Wengel J. Novel convenient syntheses of LNA [2.2.1] bicyclo nucleosides. Tetrahedron Lett. 1998;39:4381–4384. doi: 10.1016/S0040-4039(98)00706 0. [CrossRef] [Google Scholar]
- Briones C., Moreno M. Applications of peptide nucleic acids (PNAs) and locked nucleic acids (LNAs) in biosensor development. Anal. Bioanal. Chem. 2012;402:3071–3089. doi: 10.1007/s00216-012-5742-z. [PubMed] [CrossRef] [Google Scholar]
- Natsume T., Ishikawa Y., Dedachi K., Tsukamoto T., Kurita N. Effect of base mismatch on the electronic properties of DNA–DNA and LNA–DNA double strands: density functional theoretical calculations. Chem. Phys. Lett. 2007; 446:151–158. doi: 10.1016/j. cplett.2007.07.095. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Obika S., Nanbu D., Hari Y., Andoh J., Morio K., Doi T., et al. Stability and structural features of the duplexes containing nucleoside analogs with a fixed N-type conformation, 2’-O,4’-C-methyleneribonucleosides. Tetrahedron Lett. 1998;39:5401–5404. doi: 10.1016/ S0040-4039(98)01084-3. [CrossRef] [Google Scholar]
- Fang S., Lee H.J, Wark A.W., Corn R.M. Attomole microarray detection of microRNAs by nanoparticle-amplified SPR imaging measurements of surface polyadenylation reactions. J. Am. Chem. Soc. 2006;128:14044–14046. doi: 10.1021/ja065223p. [PMC free article] [PubMed] [CrossRef] [Google Scholar]
- Zhang L, Peritz A, Meggers E (March 2005). “A simple glycol nucleic acid”. Journal of the American Chemical Society. 127 (12): 4174–5. doi:10.1021/ja042564z. PMID 15783191.
- Schlegel MK, Essen LO, Meggers E (July 2008). “Duplex structure of a minimal nucleic acid”. Journal of the American Chemical Society. 130 (26): 8158–9. doi:10.1021/ja802788g. PMC 2816004. PMID 18529005.
- Schlegel MK, Essen LO, Meggers E (February 2010). “Atomic resolution duplex structure of the simplified nucleic acid GNA”. Chemical Communications. 46 (7): 1094–6. doi:10.1039/ B916851F. PMID 20126724.
- Schöning, K. U. et al. Chemical etiology of nucleic acid structure: the a-threofuranosyl-(3’-->2’) oligonucleotide system. Science 290, 1347-1351, (2000)
- Eschenmoser, A. Chemical etiology of nucleic acid structure. Science 284, 2118-2124, (1999).
- Dunn, Matthew R.; Larsen, Andrew C.; Zahurancik, Walter J.; Fahmi, Nour Eddine; Meyers, Madeline; Suo, Zucai; Chaput, John C. (2015-04-01). “DNA Polymerase-Mediated Synthesis of Unbiased Threose Nucleic Acid (TNA) Polymers Requires 7-Deazaguanine To Suppress G: G Mispairing during TNA Transcription”. Journal of the American Chemical Society. 137 (12): 4014–4017. doi:10.1021/ja511481n. ISSN 0002-7863.
- Culbertson, M. C. et al. Evaluating TNA stability under simulated physiological conditions. Bioorg. Med. Chem. Lett. 26, 2418-2421, (2016).
- Sau, S. P., Fahmi, N. E., Liao, J.-Y., Bala, S. & Chaput, J. C. A scalable synthesis of α-L-threose nucleic acid monomers. J. Org. Chem. 81, 2302-2307, (2016).
- Larsen, A. C. et al. A general strategy for expanding polymerase function by droplet microfluidics. Nat. Commun. 7, 11235, (2016).
- Nikoomanzar, A., Vallejo, D. & Chaput, J. C. Elucidating the Determinants of Polymerase Specificity by Microfluidic-Based Deep Mutational Scanning. ACS Synth. Biol. 8, 1421 1429, (2019).
- Yu, H., Zhang, S. & Chaput, J. C. Darwinian evolution of an alternative genetic system provides support for TNA as an RNA progenitor. Nat. Chem. 4, 183-187, (2012).
- Mei, H. et al. Synthesis and Evolution of a Threose Nucleic Acid Aptamer Bearing 7-Deaza 7-Substituted Guanosine Residues. J. Am. Chem. Soc. 140, 5706-5713, (2018).
- Rangel, A. E., Chen, Z., Ayele, T. M. & Heemstra, J. M. In vitro selection of an XNA aptamer capable of small-molecule recognition. Nucleic Acids Res. 46, 8057-8068, (2018).
- Pinheiro, V. B. et al. Synthetic genetic polymers are capable of heredity and evolution. Science 336, 341-344, (2012).
- Chim, N., Shi, C., Sau, S. P., Nikoomanzar, A. & Chaput, J. C. Structural basis for TNA synthesis by an engineered TNA polymerase. Nat. Commun. 8, 1810, (2017).
- Jackson, L. N., Chim, N., Shi, C. & Chaput, J. C. Crystal structures of a natural DNA polymerase that functions as an XNA reverse transcriptase. Nucleic Acids Res., (2019).
- Orgel, L. E. A simpler nucleic acid. Science 290, 1306-1307, (2000).
- Liu, L. S. et al. alpha-l-Threose Nucleic Acids as Biocompatible Antisense Oligonucleotides for Suppressing Gene Expression in Living Cells. ACS Appl Mater Interfaces 10, 9736-9743, (2018).
- Non-viral Vectors in Gene Therapy: Recent Development, Challenges, and Prospects; AAPS Journal, Volume 23, article number 78, (June 21, 2021), Non-viral Vectors in Gene Therapy: Recent Development, Challenges, and Prospects | The AAPS Journal (springer.com)
- Non-Viral Delivery Systems in Gene Therapy, Gene Therapy - Tools and Potential Applications, Edited by Francisco Martin Molina, 27 February 2013, DOI: 10.5772/52704 Non-Viral Delivery Systems in Gene Therapy | IntechOpen
- Long Term Follow-Up After Administration of Human Gene Therapy Products; Guidance for Industry, January 2020, Long Term Follow-Up After Administration of Human Gene Therapy Products; Guidance for Industry (fda.gov).
- BioNTech - https://biontech.de/
Author Details
Robert Dream - HDR COMPANY LLC
Publication Details
This article appeared in American Pharmaceutical Review: Vol. 27, No. 4May/June 2024Pages: 16-25
Subscribe to our e-newsletters
Stay up to date with the latest news, articles, and events. Plus, get special
offers from American Pharmaceutical Review delivered to your inbox!
Sign up now!